FieldDesk: Agentic Workflow Infrastructure for Administrative Readiness
Published:
At the SCSP 2026 National Security Technology Hackathon in Washington, D.C., I built FieldDesk, a prototype for military administrative readiness. FieldDesk won the DC first-phase GenAI.mil track qualifier, which advanced the project from the local first round.
The useful part was not the award. It was the technical question the prototype forced:
What should exist around a model before it can safely help with high-trust administrative work?
FieldDesk is my answer to that question in one workflow.
It is not a regulation chatbot. It is an agentic workflow system that takes mission intent, searches controlled sources, maps evidence to requirements, catches gaps, runs deterministic checks, and produces a review-ready action package for a human.
The product surface is military administration. The technical pattern is broader:
controlled sources
-> tool-using agent
-> structured extraction
-> deterministic verification
-> source-backed workflow state
-> human-review package
That is the layer around the model.
The hackathon context
The event was SCSP’s 2026 National Security Technology Hackathon, hosted as part of the AI+ Expo ecosystem. SCSP describes the hackathon as bringing together AI engineers from academia, research institutions, the private sector, and government to build applications for national competitiveness and national security.
The first phase took place across San Francisco, Boston, and Washington, D.C. Teams built prototypes in tracks including Cloud Laboratories, Electric Grid Optimization, Wargaming, and GenAI.mil. FieldDesk won the GenAI.mil track for the Washington, D.C. first phase. The GenAI.mil track focused on AI tools for military administrative work, logistics, and tactical knowledge retrieval for rank-and-file users.
That framing was useful because it constrained the build. The prototype had to target a concrete user, a concrete workflow, and a concrete failure mode.
The workflow
The first workflow is TDY travel readiness.
A user enters mission intent:
Send 10 soldiers to Demo Training Site for training from June 10-14. Lodging and rental vehicles required.
FieldDesk turns that sentence into structured workflow state:
workflow: TDY travel
purpose: training
destination: Demo Training Site
dates: June 10-14
travelers: 10
lodging: required
rental vehicles: required
Then the agent searches mocked sources that represent the systems a real workflow would touch:
- coordination messages
- document repositories
- rosters
- training orders
- GSA-style rate data
- JTR-style policy excerpts
- local SOPs and unit checklists
- uploaded corrections
- DTS-style export fields
The initial run intentionally contains problems:
- the mission says 10 travelers, but the roster only shows 8
- no funding memo is present
- the rental vehicle justification is too generic for review
FieldDesk surfaces those as review blockers before the package reaches a human reviewer. After the user stages corrections, the system recomputes readiness and generates a package with evidence map, reviewer objections, action list, packet summary, export rows, and source-backed trace.
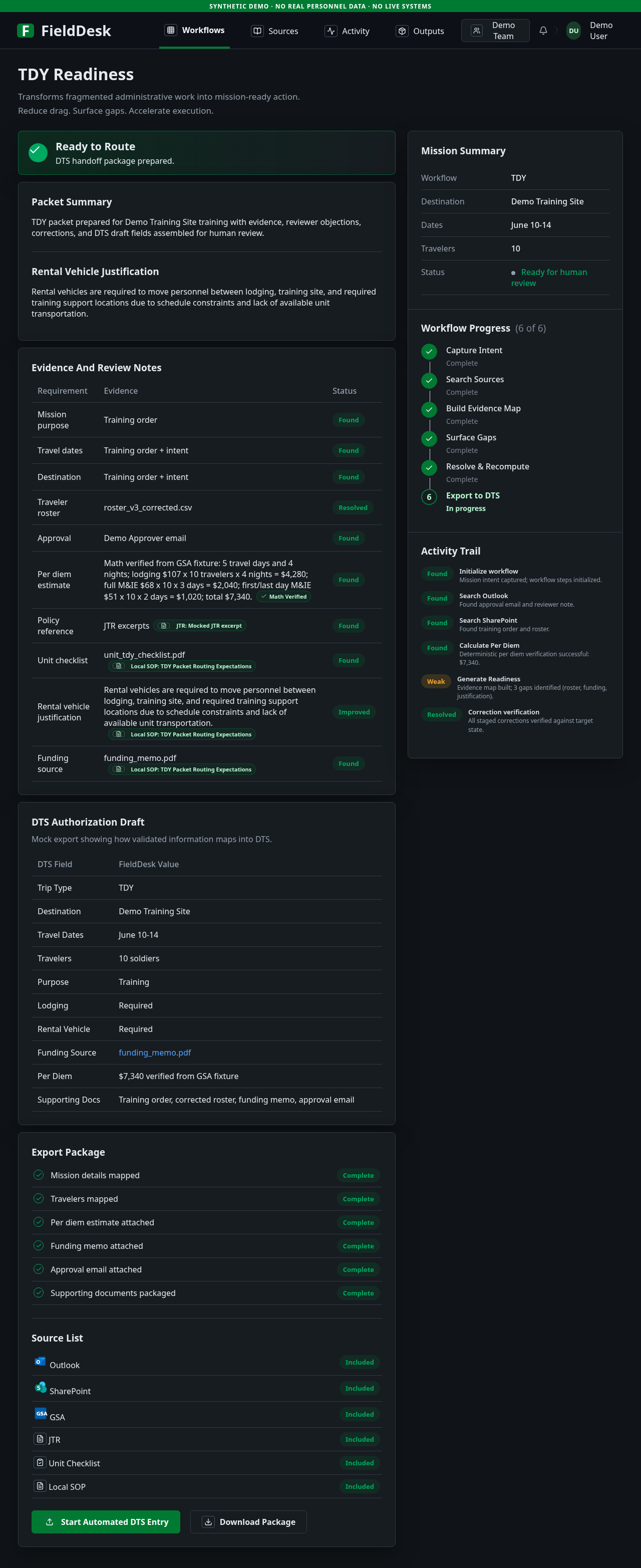
FieldDesk synthetic demo. The screenshot shows the final readiness package after corrections are staged: evidence map, reviewer notes, deterministic per diem verification, workflow progress, and export-oriented fields. All visible data is synthetic.
The core value moment is simple:
catch avoidable administrative failure before review.
The architecture
The prototype is a TypeScript / Next.js application with a controlled agent runtime.
The important design choice is the boundary between semantic reasoning and deterministic verification.
intent
-> source selection
-> agent tool loop / synthesis
-> structured output schema
-> deterministic rules
-> validated workflow object
-> review package
The model owns semantic work:
- interpreting mission intent
- choosing relevant source tools
- extracting facts from documents and messages
- identifying gaps and conflicts
- drafting reviewer objections and next actions
The application owns system controls:
- which sources are available
- which corrections have been staged
- which tools the agent can call
- schema validation
- per diem arithmetic
- audit trace construction
- final API contract
This boundary matters because high-trust workflows should not put all correctness inside the model. The model can reason over messy context, but the platform should control what data exists, what tools can run, what math is trusted, what output shape is valid, and what a human can inspect.
A model response is not a workflow state.
A workflow state needs source references, typed fields, validation, deterministic checks, and a path to human review.
Tool use over open-ended chat
The autonomous path uses fixture-backed tools instead of open-ended search.
That was intentional. In the public prototype, the tools are mocked. In a real environment, the same boundary would represent approved connectors into systems such as email, document stores, policy references, rate tables, and workflow systems.
The agent loop is bounded:
- The model chooses a tool call.
- The API validates the tool arguments.
- The tool executes against controlled fixture data.
- The observation is appended to agent state.
- The loop continues until the model returns a final synthesis or reaches a step limit.
- The final object passes schema validation and deterministic checks.
That is a different product shape from a blank chat box.
A blank chat box asks the user to know what to ask. FieldDesk asks the system to know what the workflow requires.
Deterministic checks outside the model
Some parts of the workflow should not be delegated to the model.
Per diem arithmetic is one example. FieldDesk lets the model extract trip facts and reason over evidence, but the application verifies rate calculations using deterministic rules.
That pattern generalizes:
- let the model interpret messy language
- keep arithmetic in code
- keep source availability explicit
- keep output schemas strict
- keep human-review artifacts inspectable
The goal is not to distrust the model. The goal is to put the model in the right part of the system.
Scaling across the Department
The TDY workflow is only one instance of a broader pattern.
The scalable version of FieldDesk is not one central team hard-coding every administrative process. It is a workflow layer where units can create, improve, and share operational workflows with each other.
A battalion that has already encoded a good travel-readiness workflow should not force every other battalion to rediscover the same checklist, source mapping, reviewer objections, and export fields. The useful artifact is not just the completed packet. It is the reusable workflow:
workflow template
-> required sources
-> extraction schema
-> deterministic checks
-> reviewer questions
-> export format
-> local unit adjustments
That makes the system compounding. One unit can build a workflow for TDY packets. Another can adapt it for equipment turn-in. Another can encode a recurring training-readiness process. Over time, this points toward a Department-wide library of source-backed workflows that preserve local context without making every unit start from a blank chat box.
The important governance boundary is that shared workflows should be inspectable before they are adopted. A unit should be able to see what sources a workflow expects, what fields it extracts, what checks it runs, what assumptions it makes, and where human approval remains required.
The end-state product thesis is not a single giant assistant. It is a shared workflow graph for administrative readiness: reusable enough to spread across units, local enough to adapt to mission context, and structured enough to keep evidence and accountability intact.
Evaluation
FieldDesk includes a small evaluation harness around the demo workflow.
The evals use a golden scenario for the TDY case and check both exact fields and semantic quality:
- exact checks for structured fields like dates, travelers, and estimated totals
- expected initial output before corrections
- expected corrected output after staged fixes
- tool-loop tests for source retrieval behavior
- deterministic-rule tests for calculation logic
- LLM-as-judge grading for groundedness and reasoning quality
This is still a hackathon prototype, so the evals are small. But the principle matters.
For operational AI, evaluation has to move closer to the workflow. It is not enough to ask whether the model can answer a policy question. The system has to be evaluated on whether it helps a user produce a better package under realistic constraints:
- Did it find the right sources?
- Did it expose missing evidence?
- Did it distinguish weak evidence from strong evidence?
- Did deterministic checks catch errors?
- Did the final package help a reviewer inspect the decision?
Those are systems questions, not only model questions.
Why this matters
Administrative work is easy to dismiss because it looks like paperwork.
But paperwork is often how organizations coordinate action. It decides whether people move, equipment arrives, travel happens, funding is available, permissions are granted, and plans become executable.
If that layer is slow, the organization is slow.
The right AI system should compress the evidence surface without hiding accountability. It should preserve sources, surface gaps, and help humans make better decisions faster.
That is why FieldDesk is not framed as “automating paperwork” in the simplistic sense. The technical goal is administrative readiness:
less hunting
less rework
clearer gaps
typed workflow state
source-backed outputs
human-reviewable packages
Scope and safety
FieldDesk is a hackathon prototype, not a production military system.
The public repository uses synthetic demo data only. It does not include personal records, credentials, operational records, or government output. The connectors are mocked to show the workflow pattern without requiring access to production systems.
That constraint is intentional. The public demo is meant to make the product shape inspectable:
- agent-led evidence gathering
- controlled tool use
- structured extraction
- gap detection
- correction staging
- deterministic verification
- reviewer-ready output
The real work would be integrating the same patterns into approved environments, approved data sources, and accountable review processes.
What I learned
The strongest AI products for government will probably not look like generic assistants.
They will look like workflow systems with models inside them.
The model will reason, but the product will define the task boundary. The product will decide what sources exist, what evidence counts, what output schema is valid, where uncertainty is shown, what a reviewer can inspect, and which actions require human approval.
That is the thread connecting FieldDesk, ATO Copilot, and the systems I keep building:
high-trust work needs source-backed AI, not just fluent AI.
The bottleneck is shifting from access to model capability toward the ability to wrap that capability in systems that preserve evidence, judgment, and accountability.
FieldDesk is a small prototype pointed at that shift.
The prototype is public here: https://github.com/EthanHNguyen/FieldDesk
Sources: SCSP Hackathon, AI+ Expo Hackathon, FieldDesk repository.